Pydap is a pure Python library implementing the Data Access Protocol. You can use Pydap as a client to access hundreds of scientific datasets in a transparent and efficient way through the internet; or as a server to easily distribute your data from a variety of formats.
Pydap is both client and server application to access netcdf/grib/HDF data. You use it to read the data but also to serve it throught opendap. The server has opendap and also the ability to server the data using WMS for gridded datasets. You can get the map tabs by installing the pydap.responses.wms module; the web UI will automatically pick it up and show the map if the dataset has any variables that can be displayed.
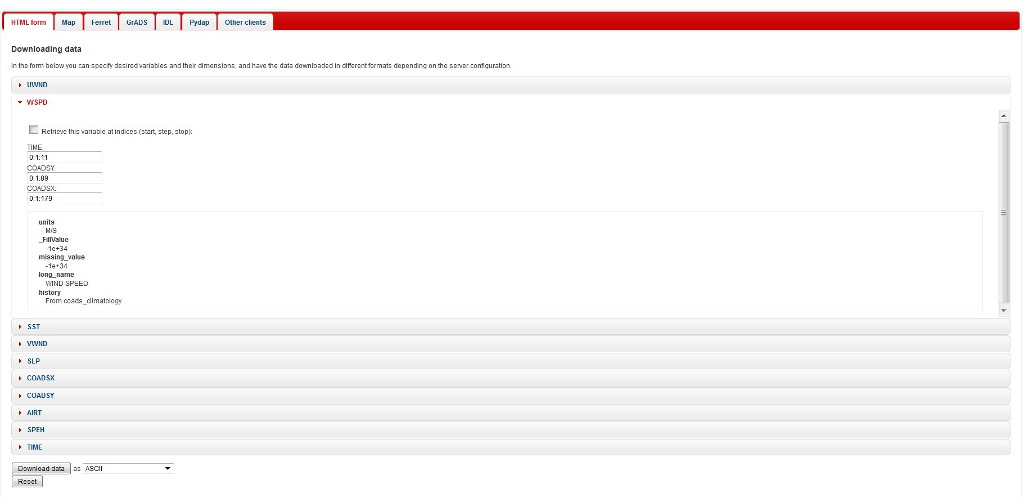
Pydap server also provide the code to acces the data with different opendap clients. It provides the ferret/Grads/IDL and pydap output itself:
$ python
>>> from pydap.client import open_url
>>> dataset = open_url(“https://pydap.oceandrivers.com/coads.nc”)
>>> import pprint
>>> pprint.pprint( dataset.keys() )
‘WSPD’,
‘SST’,
‘VWND’,
‘SLP’,
‘COADSX’,
‘COADSY’,
‘AIRT’,
‘SPEH’,
‘TIME’]
Check our installation to see it working. https://pydap.oceandrivers.com/coads.nc.html
We asked Roberto de Almeida about the history of PyDAP:
Roberto de Almeida
